

SYNOPSIS
Virtualization is one of the hottest technologies to hit IT in years, with Microsoft’s Hyper-V R2 release igniting those flames even further. Hyper-V arrives as a cost-effective virtualization solution that can be easily implemented by even the newest of technology generalists. But while Hyper-V itself is a trivial implementation, ensuring its highest levels of redundancy, availability, and most importantly performance are not. Due to virtualization’s heavy reliance on storage, two of the most critical decisions you will make in implementing Hyper-V are where and how you’ll store your virtual machines.
With the entry of enterprise-worthy iSCSI solutions into the market, IT environments of all sizes can leverage the very same network infrastructure they’ve built over time to host that storage. This already-present network pervasiveness combined with the dynamic nature of virtualization makes iSCSI a perfect fit for your storage needs. But correctly connecting all the pieces, however, can be a challenge. To help, The Shortcut Guide to Architecting iSCSI Storage for Microsoft Hyper-V digs deep into the decisions that environments large and small must consider. It looks at best practices for Hyper-V storage topologies and technologies, as well as cost and manageability implications for the solutions available on the market today.
CHAPTER PREVIEWS
Chapter 1: The Power of iSCSI in Microsoft Virtualization
Virtualization solutions such as Hyper-V enable many fantastic optimizations for the IT environment: VMs can be easily backed up and restored in whole, making affordable server restoration and disaster recovery possible. VM processing can be load balanced across any number of hosts, ensuring that you’re getting the most value out of your server hardware dollars. VMs themselves can be rapidly deployed, snapshotted, and reconfigured as needed, to gain levels of operational agility never before seen in IT.
Yet at the same time virtualization also adds levels of complexity to the IT environment. Gone are the traditional notions of the physical server "chassis" and its independent connections to networks and storage. Replacing this old mindset are new approaches that leverage the network itself as the transmission medium for storage. With the entry of enterprise-worthy iSCSI solutions into the market, IT environments of all sizes can leverage the very same network infrastructure they’ve built over time to host their storage as well. This already-present network pervasiveness combined with the dynamic nature of virtualization makes iSCSI a perfect fit for your storage needs.
Correctly connecting all the pieces, however, is the challenge. To help, this guide digs deep into the decisions that environments large and small must consider. It looks at best practices for Hyper-V storage topologies and technologies, as well as cost and manageability implications for the solutions available on the market today. Both this and the following chapter will start by discussing the technical architectures required to create a highly-available Hyper-V infrastructure. In Chapter 2, you’ll be impressed to discover just how many ways that redundancy can be inexpensively added to a Hyper-V environment using native tools alone.
If, like many, your storage experience is thus far limited to the disks you plug directly into your servers, you’ll be surprised at the capabilities today’s iSCSI solutions offer. Whereas Chapters 1 and 2 deal with the interconnections between server and storage, Chapter 3 focuses exclusively on capabilities within the storage itself. Supporting features such as automatic restriping, thin provisioning, and built-in replication, today’s iSCSI storage provides enterprise features in a low-cost form factor.
Finally, no storage discussion is fully complete without a look at the affordable disaster recovery options made available by virtualizing. Chapter 4 discusses how iSCSI’s backup, replication, and restore capabilities make disaster recovery solutions (and not just plans) a real possibility for everyone.
But before we delve into those topics, we first need to start with your SAN architecture itself. That architecture can arguably be the center of your entire IT infrastructure.
Chapter 2: Creating Highly-Available Hyper-V
It's worth saying again that Hyper-V alone is exceptionally easy to set up. Getting the basics of a Hyper-V server up and operational is a task that can be completed in a few minutes and with a handful of mouse clicks. But in the same way that building a skyscraper is so much more than welding together a few I-beams, creating a production-worthy Hyper-V infrastructure takes effort and planning to be successful.
The primary reason for this dissonance between "installing Hyper-V" and "making it ready for operations" has to do with high availability. You can think of a Hyper-V virtual infrastructure in many ways like the physical servers that exist in your data center. Those servers have high-availability functions built-in to their hardware: RAID for drive redundancy, multiple power supplies, redundant network connections, and so on. Although each of these is a physical construct on a physical server, they represent the same kinds of things that must be replicated into the virtual environment: redundancy in networking through multiple connections and/or paths, redundancy in storage through multipathing technology, redundancy in processing through Live Migration, and so on.
Using iSCSI as the medium of choice for connecting servers to storage is fundamentally useful because of how it aggregates "storage" beneath an existing "network" framework. Thus, with iSCSI it is possible to use your existing network infrastructure as the transmission medium for storage traffic, all without needing a substantially new or different investment in infrastructure.
To get there, however, requires a few new approaches in how servers connect to that network. Hyper-V servers, particularly those in clustered environments, tend to make use of a far, far greater number of network connections than any other server in your environment. With interfaces needed for everything from production networking to storage networking to cluster heartbeat, keeping straight each connection is a big task.
This chapter will discuss some of the best practices in which to connect those servers properly. It starts with a primer on the use of the iSCSI Initiator that is natively available in Windows Server 2008 R2. You must develop a comfort level with this management tool to be successful, as Hyper-V's high level of redundancy requirements means that you'll likely be using every part of its many wizards and tabs. In this section, you'll learn about the multiple ways in which connections are aggregated for redundancy. With this foundation established, this chapter will continue with a look at how and where connections should be aggregated in single and clustered Hyper-V environments.
Chapter 3: Critical Storage Capabilities for Highly-Available Hyper-V
Chapter 2 highlighted the fact that high availability is fundamentally critical to a successful Hyper-V infrastructure. This is the case because uncompensated hardware failures in any Hyper-V infrastructure have the potential to be much more painful than what you're used to seeing in traditional physical environments.
A strong statement, but think for a minute about this increased potential for loss: In any virtual environment, your goal is to optimize the use of physical equipment by running multiple virtual workloads atop smaller numbers of physical hosts. Doing so gives you fantastic flexibility in managing your computing environment. But doing so, at the same time, increases your level of risk and impact to operations. When ten workloads, for example, are running atop a single piece of hardware, the loss of that hardware can affect ten times the infrastructure and create ten times the pain for your users.
Due to this increased level of risk and impact, you must plan appropriately to compensate for the range of failures that can potentially occur. The issue here is that no single technology solution compensates for every possible failure. Needed are a set of solutions that work in concert to protect the virtual environment against the full range of possibilities.
Depicted in Figure 3.1 is an extended representation of the previous chapter's fully-redundant Hyper-V environment. There, each Hyper-V server connects via multiple connections to a networking infrastructure. That networking infrastructure in turn connects via multiple paths to the centralized iSCSI storage infrastructure. Consider for a minute which failures are compensated for through this architecture:
- Storage and Production Network traffic can survive the loss of a single NIC due to the incorporation of 802.3ad network teaming and/or MPIO/MCS.
- Storage and Production Network traffic can also survive the loss of an entire network switch due to the incorporation of 802.3ad network teaming and/or MPIO/MCS that has been spread across multiple switches.
- Virtual machines can survive the planned outage of a Hyper-V host through Live Migration as a function of Windows Failover Clustering.
- Virtual machines can also be quickly returned to service after the unplanned outage of a Hyper-V host as a function of Windows Failover Clustering.
- Network oversubscription and the potential for virtual machine denial of service are inhibited through the segregation of network traffic across Storage, Production, Management, and Heartbeat connections.
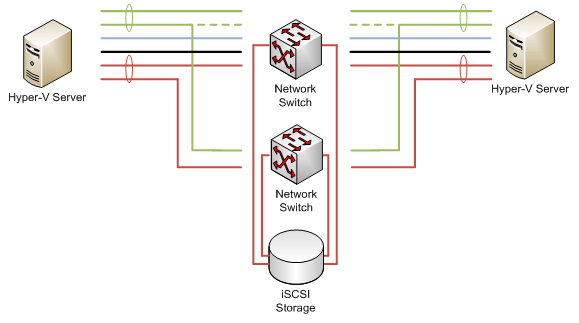
Figure 3.1: Hyper-V environments require a set of solutions to protect against all of the possible failures.
The risk associated with each of these potential failures has been mitigated through the implementation of multiple layers of redundancy. However, this design hasn't necessarily taken into account its largest potential source of risk and impact. Take another look at Figure 3.1. In that figure, one element remains that in and of itself can become a significant single point of failure for your Hyper-V infrastructure. That element is the iSCSI storage device itself.
Each and every virtual machine in your Hyper-V environment requires storage for its disk files. This means that any uncompensated failure in that iSCSI storage has the potential to take down each and every virtual machine all at once, and with it goes your business' entire computing infrastructure. As such, there's a lot riding on the success of your storage infrastructure. This critical recognition should drive some important decisions about how you plan for your Hyper-V storage needs. It is also the theme behind this guide's third chapter.
Chapter 4: The Role of Storage in Hyper-V Disaster Recovery
You've learned about the power of iSCSI in Microsoft virtualization. You've seen the various ways in which iSCSI storage is connected into Hyper-V. You've learned the best practices for architecting your connections along with the smart features that are necessary for 100% storage uptime. You've now got the knowledge you need to be successful in architecting iSCSI storage for Hyper-V.
With the information in this guide's first three chapters it becomes possible to create a highly-available virtual infrastructure atop Microsoft's virtualization platform. With it, you can create and manage virtual machines with the assurance that they'll survive the loss of a host, a connection, or any of the other outages that happen occasionally within a data center.
Yet this knowledge remains incomplete without a look at one final scenario: the complete disaster. That disaster might be something as substantial as a Category 5 hurricane or as innocuous as a power outage. But in every scenario, the end result is the same: You lose the computing power of an entire data center.
Important to recognize here is that the techniques and technologies that you use in preparing for a complete disaster are far, far different than those you implement for high availability. Disaster recovery elements are added to a virtual environment as an augmentation that protects against a particular type of outage.



